目录
2024年6月30日,计算机组成原理课程复习。
题型/知识点分布:
分析题:30分:
- 数据表示方法
- 中断过程分析
- 机器指令执行过程分析
计算题:40分:
- 总线带宽计算
- DRAM刷新时间计算
- 补码一位乘法计算过程
- 浮点加减计算过程
- 多体并行内存带宽的计算
设计题:30分:
- Cache地址格式设计
- CPU内存连接设计
- 机器指令格式设计
- 微指令格式设计
1 数据表示方法
1.1 前置知识
- 真值:实际的带有正负号的数值
- 机器数:将符号数字化的数值
- BCD码分为8421码,余3码和2421码。
- 8421码是以四个二进制位对应一个十进制位的表示方法,四个二进制位的权重分别是8、4、2、1(这种表示方式有6个冗余状态)。
- 8421码可以进行加法运算,如果运算结果不合法(例如
1101),则需要加上0110进行修正。

- 余3码就是在8421码的基础上加上
0011得到的。 - 2421码和8421码接近,只是四个二进制位的权重分别为2、4、2、1,并且表示0~4时最高位为0,表示5~8时最高位为1。
- 英文字符在计算机中通常用ACSII码进行表示,码表如下:
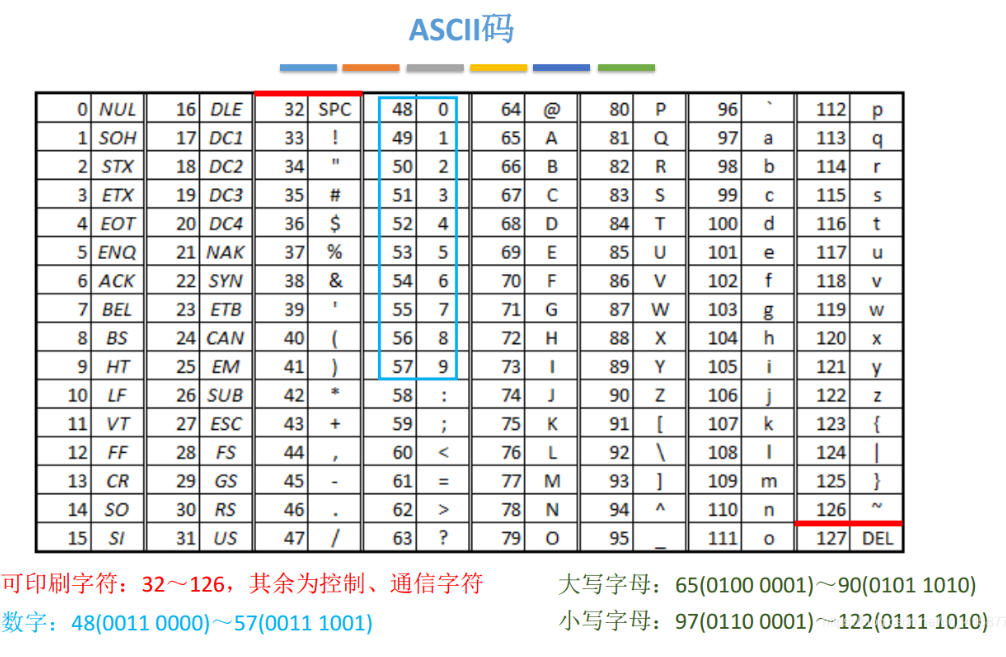
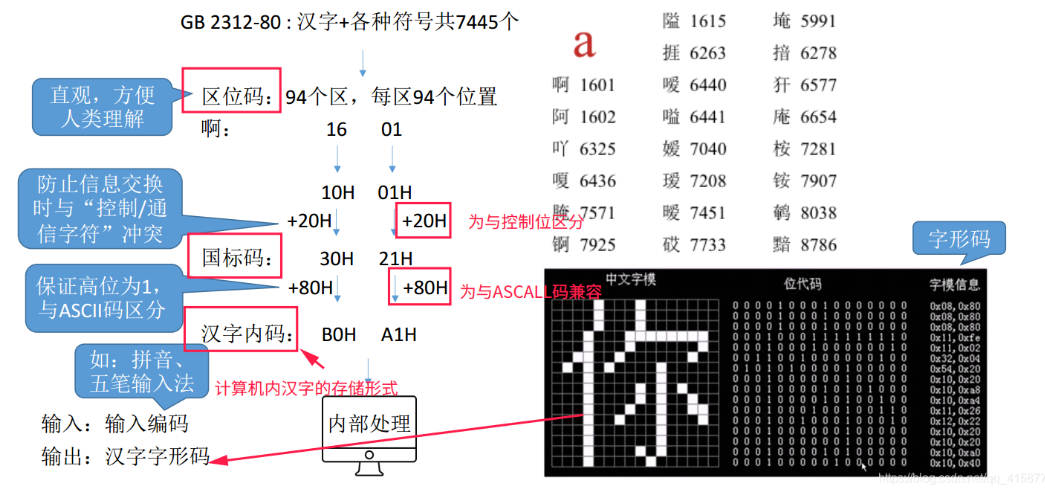
- 中文字符在计算机中用一般情况下使用GBK编码进行表示,一个汉字在计算机中的显示会经历从GBK编码(区位码)到国标码,再到机内码,最后是字形码的变化过程。
- GB编码(GB一般指代
GB2312-80,《信息交换用汉字编码字符集——基本集》,后续的GBK(K即为扩展的意思)也是在它的基础上进行发展的,原理基本一致)是最开始的一层,它的整个字符集分为94个区,每个区有94个位,每个位表示一个汉字,每个汉字都由区号和位号构成,这种编码也叫区位码。比如“万”在第45区82位,所以该汉字的GB编码为45 82。
注意,GB类汉字编码为双字节编码,因此,45相当于高位字节,82相当于低位字节。
- 为了避开ACSII码中的第0到32位,国标码规定规定汉字的表示范围为
(21, 21) ~ (7E, 7E)(HEX)(33, 33) ~ (126, 126)(DEC),所有的区位码向国标码转换时,区和位必须都要加上20H(HEX)/32(DEC)。还是以“万”为例,它的国标码是4D 72H(45 + 32再转换HEX 82 + 32再转换HEX)
注意,不严谨地说,区位码是个十进制编码,国标码和之后要说的码都是十六进制编码。
至于为什么只避开ACSII码中的前32位,一个是之后的机内码还会再把剩下的ACSII码避开,另一个是当初规定GB编码时,决定将ACSII的除空格字符以外的可打印字符,全部重编码到GB码中,以两字节表示,称之为全角字符(最能体现这一点的就是中英文下不同的标点符号:
.。);而ACSII码中的原本的这些字符,直接沿用,称之为半角字符,这些半角字符的存在也是之后会有国标码到机内码的转换的原因。
- 为了不和ACSII码的可打印字符冲突(万的国标码
4D 72H和M,r冲突),规定在国标码的基础上,每个字符的最高位从0换到1,也就是每个字节再加128,从而得到机内码(简称内码)。还是“万”,它的机内码就是CD F2(4D + 80H 72H + 80H)。
每个字符的最高位从0换到1,这句话背后指的是ACSII码一共就只有0到127,在一个字节中它的最高位一定不可能是1。所以计算机在处理字符时,如果一个字节的最高位是1,那么它就一定是中文字符,反之则为ACSII字符。
- 字形码,点阵代码的一种,为了将汉字在屏幕上显示出来,将汉字设计为点阵图所得到的点阵代码。
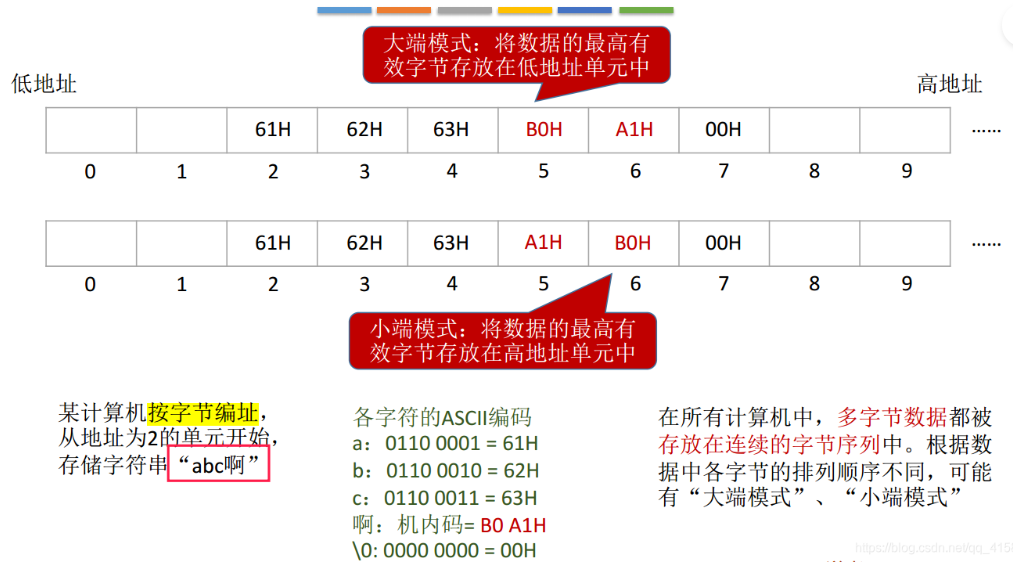
- 大端序:将数据的最高有效字节存放在低地址单元中(符合人类阅读习惯),小端序:将数据的最高有效字节存放在高地址单元中。
2 中断过程分析
2.1 前置知识
-
中断,是指计算机在执行程序的过程中,出现某些急需处理的异常情况或者特殊请求,CPU暂时中止现行程序,而转去处理这些异常情况或者特殊请求,在处理完毕之后CPU又自动返回现行程序的断点处,继续执行原程序。
-
中断系统,是指计算机实现中断功能的软、硬件总称。在CPU一侧配置了硬件上的中断机构,在设备一侧配备的中断控制接口,在软件上设计了相应的中断服务程序。
-
一个完整的中断请求,包括以下几个阶段:
- 中断请求:指中断源(引起中断的事件或者设备)向CPU发出的请求中断的要求
- 中断判优:当有多个中断源发出请求时,需要通过一些方法来决定先处理哪个中断请求
- 中断响应:指CPU中止现行程序转至中断服务程序的过程
- 中断处理:指CPU执行中断服务程序
- 中断返回:执行完中断服务程序后,CPU返回到被中断的程序继续执行
-
禁止中断:中断源发起请求中断的请求时,由于某种条件的存在,CPU不能中止现有程序的运行。这种情况称之为禁止中断。一般情况下在CPU的内部会设置一个允许中断触发器(EINT),只有在该触发器为1时,才允许CPU响应中断。允许中断触发器可以通过“开中断”和“关中断”指令来置位和复位。
-
中断屏蔽:当产生中断请求时,用程序方式有选择地封锁部分中断,而允许其他中断仍然能够得到响应。实现的方法是为每个中断源设置一个中断屏蔽触发器来屏蔽该设备的中断请求。各个设备的中断屏蔽触发器构成中断屏蔽寄存器。当然有些中断源的中断请求是不可屏蔽的。所以中断又分为可屏蔽中断和非屏蔽中断。
-
中断处理过程:
- 关中断:进入禁止中断的状态,由硬件自动实现。在保存现场的过程中,即使有更高级的中断源申请中断,CPU也不能响应。否则保存现场不完整,在中断处理完成后,也就不能正确地恢复现场并继续执行现有程序。
- 判别中断源+转入中断服务程序:在多个中断源同时请求中断的情况下,本次实际能响应的只能是优先级最高的那个中断源。
- 开中断:在整个流程中,第一次开中断将允许更高级的中断请求得到响应,实现中断嵌套。
graph TD
关中断- --> 保存断点和CPU运行程序现场
保存断点和CPU运行程序现场 --> 判别中断源+转入中断服务程序 --> 开中断- --> 执行中断服务程序 --> 关中断 --> 恢复现场和断点 --> 开中断 --> 返回断点继续执行程序
流程图会把所有的“关中断”,“开中断”识别为同一个步骤,所以加个“-”来保证流程图正确。
-
判别中断源:判断多个中断响应优先级,通常有两种方法:
- 软件查询法:由测试程序按一定优先排队次序检查各个设备的“中断触发器”。当遇到第一个“1”时,即找到了优先进行处理的中断源,取出其设备码,根据设备码转入相应的中断服务程序。
- 串行排队链法(硬件判优):由硬件确定中断源的优先与否。
-
找到优先级最高的中断请求后,一般采用中断向量法使CPU转入中断服务程序:为每一个中断源设置一个中断向量(中断服务程序的入口地址),所有的中断向量存放在主存的固定位置(中断向量表)。CPU响应某个中断源的中断请求时,根据设备提供的中断类型码,访问中断向量表,就可以找到该中断源对应的中断服务程序的入口地址。
-
中断嵌套:在处理某一个中断的过程中,又发生了新的更高级的中断源的中断请求,且CPU处于开中断的状态下,CPU就可以中断当前中断服务程序,转去执行新的中断请求所对应的中断服务程序。一般情况下,平级或者更低级的中断请求,CPU不会响应其请求。
-
中断优先级的响应次序由硬件排队线路决定,一旦设计完成就基本不会改变。在有优先级中断屏蔽码的情况下,可以不改变硬件排队线路,使其中断响应次序不同。
2.2 题目
- 在中断系统中,INTR、INT、EINT这3个触发器的作用是什么?
INT(interrupt,中断)
答案
- INTR是中断请求触发器,每个中断源对应一个INTR,当其为1时表示该中断源有中断请求。
- EINT是允许中断触发器,当其为1时表示CPU允许响应中断源的请求;当其为0时表示CPU禁止响应中断。
- INT是中断标记触发器,当其为1时,表示CPU进入中断周期。
- 什么是中断隐指令?有什么作用?
答案
- 中断隐指令指硬件在中断响应周期内自动完成的动作。
- 作用包括保存程序断点、硬件关中断、向量地址送PC(硬件向量法)或中断识别程序入口地址送PC(软件查询法)。
- 某机有5个中断源L0、L1、L2、L3、L4,中断响应的优先次序为L0->L1->L2->L3->L4,要求将中断处理次序改为L1->L4->L2->L0->L3,根据下面的格式,写出各中断源的屏蔽字。
| 中断源 | 屏蔽字 | 屏蔽字 | 屏蔽字 | 屏蔽字 | 屏蔽字 |
|---|---|---|---|---|---|
| \ | L0 | L1 | L2 | L3 | L4 |
| L0 | |||||
| L1 | |||||
| L2 | |||||
| L3 | |||||
| L4 |
答案
| 中断源 | 屏蔽字 | 屏蔽字 | 屏蔽字 | 屏蔽字 | 屏蔽字 |
|---|---|---|---|---|---|
| \ | L0 | L1 | L2 | L3 | L4 |
| L0 | 1 | 0 | 0 | 1 | 0 |
| L1 | 1 | 1 | 1 | 1 | 1 |
| L2 | 1 | 0 | 1 | 1 | 0 |
| L3 | 0 | 0 | 0 | 1 | 0 |
| L4 | 1 | 0 | 1 | 1 | 1 |
按照中断处理次序,对于每个中断源而言,它后面的所有中断源(包括自己)的屏蔽字为1,其余均为0。
- 设某机配有A、B、C三个设备,其响应优先级次序为A->B->C,为改变中断处理次序,它们的中断屏蔽字如下:
| 设备 | 屏蔽字 |
|---|---|
| A | 111 |
| B | 010 |
| C | 011 |
按下图画出CPU执行程序的轨迹,设A、B、C中断服务程序的执行时间均为20us。
答案
先按照中断处理次序到屏蔽字的转换方法,反向还原出中断处理次序:A->C->B(1越多,越优先)。
之后再按照这个中断处理次序画图。
- 一开始是A,它会被首先响应,也会被优先处理,所以第一个是A一直到20us过去执行完毕。
- 之后是B,它会被响应,但是处理优先级比C低,所以B被处理的过程中响应了C。
- C被响应,并且处理优先级比B高,所以C先执行20us完成。
- C执行完成后,还剩B的10us,执行完成即可。
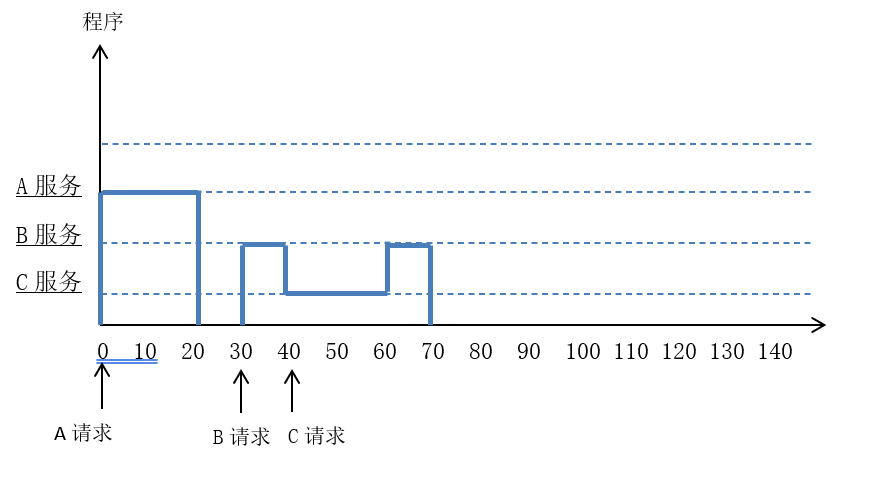
注意,ABC在什么时候请求是题目会给定的。实际要画得只有蓝色的线。

3 机器指令执行过程分析
4 总线带宽计算
4.1 前置知识
- 总线带宽:一定时间内,总线上可以传输的数据量,使用MBytes/s表示。
- 总线位宽:总线能够同时传输的位数,使用bit表示(常见有32位,64位)。
- 总线频率:频率用MHz表示,频率越高,工作效率越高。
- 单位:Mbps = megabits per second,每秒传输的位数量;MBps就是每秒传输的字节数量。
4.2 题目
- 设总线的时钟频率为8MHz,一个总线周期等于一个时钟周期。如果一个总线周期并行传送16位数据,问总线带宽是多少?
答案
因为一个总线周期等于一个时钟周期,所以总线的频率即为8MHz,也就是说1s内,传输8M次数据,所以实际传输的数据为,因为8位为1字节,所以
- 在一个32位系统总线中,总线的时钟频率为66MHz,假设总线最短传输周期为4个时钟周期,计算最大的数据传输率。若想提高数据传输率,可采取什么措施?
答案
- 因为一个总线最短传输周期为4个时钟周期,所以总线的频率为;又因为该总线是32位的,所以一次传输可以传输4个字节,所以总线的最大数据传输率为。
- 提高总线时钟频率,增加总线宽度,减少总线传输周期包含的时钟周期。
5 DRAM刷新时间计算
5.1 前置知识
- DRAM需要定时刷新,原因在于存储单元的访问时随机的,有可能某些存储单元长时间得不到访问,不进行存储器的读/写操作,其存储单元内的信息将会慢慢消失。为此必须采取定时刷新的方法,它规定在一定的时间内,对动态RAM的全部基本单元必作一次刷新,一般取2ms作为刷新周期。
- DRAM的刷新一般有三种方式:集中刷新,分散刷新,异步刷新。
- 集中刷新,指的是在规定的一个刷新周期内,对全部的行集中一段时间逐行进行刷新,此刻必须停止读写操作。用DRAM存储单元数×存取周期这一段时间来对所有存储单元进行刷新,这期间内不能进行读写,称为死区。
- 分散刷新,指的是将对每行存储单元的刷新分散到每个存储周期内完成,将每个存储单元的存储周期分成两段,前半段用来读/写,后半段用来刷新。这样每有x次读写操作,就会刷新第0行到第x行。这种方式对于整个内存来说就没有死区,但是延长了读写速度,整个系统的速度就降低了。
- 异步刷新:规定在一个刷新周期内对所有的行进行一次刷新。假设有x行,刷新周期为2ms,那么也就是说每隔ms就要刷新一个行。这样刷新一次只会停止一个读写周期,但对每一行来说,刷新周期仍然为2ms,死区仍然为一个读写周期,死区仍然不变。
5.2 题目
一个位的动态RAM芯片,内部排列结构排列成形式,存取周期为。问采用集中刷新、分散刷新和异步刷新的刷新间隔各为多少?(设刷新周期为2ms)
| 刷新间隔 | 访存死区 | |
|---|---|---|
| 集中刷新 | ||
| 分散刷新 | ||
| 异步刷新 |
答案
| 刷新间隔 | 访存死区 | |
|---|---|---|
| 集中刷新 | ||
| 分散刷新 | 无 | |
| 异步刷新 | ,7.8125us内有78个存取周期,其中有一个周期用于刷新,剩余的0.0125us再加上这个用于刷新的周期就是异步刷新的死区: |
6 补码一位乘法计算过程
6.1 前置知识
- 补码:正数和0的补码是自身,负数的补码是将对应正数按位取反,最后在最小的位上+1。
- 补码一位乘步骤:
- 假设两个乘数分别是X、Y,分别求出X、-X、Y的补码。X和——X的补码写成双符号位的形式。
- 按照X补码的长度,设定相同长度的部分积,值为全0,并且给Y的补码的末尾加一位0。
- 之后重复这个步骤:查看补0之后的Y的补码的最后两位,如果是00或者11,就把部分积和Y补码一起右移一位;如果是01,就在之前的部分积的基础上加上X的补码再右移一位;如果是10,就在之前的部分积的基础上加上-X的补码再右移一位。重复这个步骤,直到Y的小数点后只剩一位,再判断一次并且相加,这一次不移位。
- 步骤3完成后,部分积的结果连接上Y补码最后那个版本剔除掉Y补码原本部分所剩下的部分,连在一起就是X乘Y的结果的补码,再求原码即可得到结果。
注意“右移一位”操作,部分积和Y补码连起来整体向右移一位,右边多出来的一位直接废弃,左边新加的一位取决于符号位,符号位是1就新加1,符号位是0就新加0。结束步骤三循环的条件也可以是废弃的位数等于Y的数位数量(不包括符号位)。
6.2 题目
用补码一位乘算法,两位乘计算。(X = 0.110 111,Y = -0.101 110)
考试时,数值位为4位,设A =
0.1101,B =-0.1010,计算的结果会写在之后。

7 浮点加减计算过程
7.1 前置知识
7.2 题目
用补码运算步骤计算,其中,采用双符号位,阶码共4位,尾数共8位。若有舍入,采用0舍1入法。
8 多体并行内存带宽的计算
8.2 题目
一个4体低位交叉的存储器,假设存取周期为T,CPU每隔存取周期启动一个存储体,问访问地址连续的64个字需要多少存取周期?
答案
4体交叉,存储器由4个模块组成。CPU每隔存取周期送出一个地址,连续给出4个,存储器依次返回4个字,这4个字分别来自4个模块。存取每个字的时间均为T,由于多模块并行工作,所以从存储器外部观察,完成第一个字的读写后,后面3个字只需就完成了读写。
- 连续访问4个字的时间为:
- 连续访问64个字的时间为:。
9 Cache地址格式设计
9.2 题目
- 设主存按字编址,容量为256K字,Cache容量为2K字,字块长度为4。
- 设计Cache的地址格式,Cache中可装入多少块数据?
- 在直接映射方式下,设计主存地址格式。
- 在4路组相联映射方式下,设计主存地址格式。
- 在全相连映射方式下,设计主存地址格式。
- 若字长为32位,存储器按字节寻址,写出上述三种映射方式下主存的地址格式。
答案
- Cache容量为2K字,块长为4,则共有块,地址格式如下:
块地址:9位 块内地址:2位 - 主存为字,则地址线一共18根,根据第一问,主存块标记为位,可得主存的地址格式如下:
主存字块标记:7位 Cache字块地址:9位 字块内地址:2位 - 4路组相联映射,Cache中的字块每4个为一组,则Cache中有组,则组地址为7位。主存字块标记升为9位。
主存字块标记:9位 Cache字块地址:7位 字块内地址:2位 - 全相联映射方式下,主存块标记为位。
主存字块标记:16位 块内地址:2位 - 主存容量为:字节,共20根地址线,Cache容量为:字节,字块大小4个字,字节,所有方式字块内地址增加到4位。
- 一个组相联映射的Cache由64块组成,每组包含4块(4路组相联)。主存有4096块,每块由128字组成,按字寻址和编址。问主存和Cache的地址各有几位?画出主存地址格式。
答案
每块128字,块内地址需要7位;Cache组数是,组地址4位;Cache容量字,Cache地址13位;主存容量字,地址为19位。
| 主存字块标记:8位 | 组地址:4位 | 字块内地址:7位 |
|---|
10 CPU内存连接设计
10.2 题目
-
设CPU共有16根地址线,8根数据线,并用MREQ(低电平有效)作为访存控制信号,WR作为读写命令信号(高电平为读,低电平为写)。现有下列存储芯片:
- ROM:2Kx8位,4Kx8位,8Kx8位
- RAM:1Kx4位,4Kx8位,8Kx8位
- 以及74138译码器和其他门电路(门电路自定)。请选择合适芯片,画出CPU和存储器的连接图。要求:
- 最小4K位系统程序区,相邻8K用户程序区。
- 指出选用的存储芯片和数量。
- 画出片选逻辑。
-
设CPU共有16根地址线,8根数据线,并用MREQ(低电平有效)作为访存控制信号,WR作为读写命令信号(高电平为读,低电平为写)。现有下列存储芯片:
- ROM:2Kx8位,4Kx8位,8Kx8位
- RAM:1Kx4位,4Kx8位,8Kx8位
- 以及74138译码器和其他门电路(门电路自定)。请选择合适芯片,画出CPU和存储器的连接图。要求:
- 主存地址空间分配:6000H~67FFH为系统程序区;6800H~6BFFH为用户程序区
- 指出选用的存储芯片和数量。
- 画出片选逻辑。
11 机器指令格式设计
11.2 题目
- 一相对寻址的转移指令占3个字节,第一个字节是操作码,第2,3个字节是相对位移量,而且数据在存储器中以高字节地址为字地址的存放方式。假设PC当前值是4000H,问当结果为0,执行
JZ* + 35和JZ* - 17指令时,该指令的第2,3字节的大端序机器代码各为多少?(注:*为相对寻址,#为立即寻址,@为间接寻址)
答案
取出JMP指令后,PC的值为4003H;两条指令的目标地址分别为:4000H + 35 = 4000H + 23H = 4023H,4000H - 17 = 4000H - 11H = 3FEFH,所以,两条指令的相对位移量存放到两个字节中,分别为:4023H - 4003H = 32,写为补码0020H;3FEFH - 4023H = -20,写为补码FFEC;数据按大端序保存,则两条指令的第2,3字节的内容分别为:00H 20H,FFH ECH。
- 某机器主存容量为位,且存储字长等于指令字长,若该机指令系统可完成108种操作,操作码位数固定,且具有直接、间接、变址、基址、相对、立即等6种寻址方式,问:
- 画出一地址指令格式并指出各字段的作用。
- 该指令直接寻址的最大范围。
- 一次间址和多次间址的寻址范围。
- 立即数的范围(十进制表示)。
- 相对寻址的位移量(十进制表示)。
- 上述六种寻址方式的指令哪一种执行时间最短?哪一种最长?为什么?哪一种便于程序浮动?哪一种适合处理数组问题?
- 如何修改指令格式,使指令的寻址范围扩大到4M?
答案
- 单字长,一地址指令的格式:
操作码:,7位 寻址方式:,3位 形式地址:,6位 - 形式地址为6位,直接寻址的寻址单元数为个,寻址范围为0~63。
- 由于存储字长为16位,其中存放一次间址的有效地址,则一次间址的寻址单元数为字,寻址范围0~64K - 1;多次寻址时,字的首位存放间址表示,有效地址为15位,所以多次间址的寻址单元数为,寻址范围为0~32K - 1。
- 形式地址为6位,若立即数采用补码,其范围为-32~31;若为无符号数,范围为0~63。
- 由于相对寻址的位移量可正可负,所以范围为-32~31。
- 立即数方式执行时间最短,因为不需要寻址;间址方式执行时间最长,因为需要一次以上的访存;相对寻址便于程序浮动,变址寻址适合处理数组问题。
- 方案一:将指令改为双字长,第二个字全部用于存形式地址,直接寻址的单元数为,缺点是指令变长,增加取指时间;方案二:使用16位的段寄存器;方案三:使用16位的页面寄存器。
12 微指令格式设计
12.1 前置知识
- 水平型微指令:一条指令可以同时执行多个微操作,但是每一个操作都占用一个二进制位,因此水平型微指令的字长较长。
12.2 题目
- 设控制存储器容量为位,微程序可在整个控存空间转移,控制微程序转移的条件有4个(采用直接控制),微指令格式如下。问,微指令中3个字段分别为多少位?
| 操作控制 | 转移条件 | 下地址 |
|---|
答案
- 控制器一共有位,所以下地址字段有9位。
- 微程序转移条件采用直接控制,即一位表示一个转移条件,所以转移条件字段为4位。
- 因此操作控制字段为位。
- 某微程序控制器中,采用水平型直接控制,后继微指令由下地址字段给出。已知机器共有28条微指令,6个互斥的可判定外部条件,控存容量为位,设计其微指令格式并说明理由。
答案
- 水平型微指令,操作字段的位数等于微指令数,为28位。
- 控存容量为,下地址字段为9位。
- 6个互斥的外部条件,可编码为3位。
13 参考链接
本文作者:御坂19327号
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!