目录
主要内容:
- 序言部分
- LRU缓存策略实现
1 序言部分记录
缓存对于后端来说是必要的,毕竟数据库操作很耗时,不能每个请求都去读写数据库,会严重拖慢服务的速度。缓存可以将近期读取过的数据存入缓存,每次请求数据时,如果命中缓存即可直接返回缓存值。
一个分布式缓存要考虑的问题:
- 缓存淘汰策略:在缓存已满时,如何淘汰旧有缓存才能保证其余缓存在接下来的请求中命中率最高?
- 并发控制:多个请求同时到达缓存,如何设计并发控制才能保证线程安全的同时速度最快?
- 多节点通信同步:如果单机缓存已经到达性能极限,如何扩展缓存系统?如果是水平扩展,节点之间如何通信?如果是垂直扩展,扩展策略应该如何设计?
- 读写特性:缓存是否为只读?缓存是否设计淘汰时间?缓存类型是什么?
提示
一提到缓存,三个和缓存相关的问题是必须要提的,即缓存雪崩、缓存击穿和缓存穿透。
-
缓存雪崩:缓存内的大量数据的过期淘汰时间相近,使得这些数据被淘汰后,缓存未能命中大量的请求(或者缓存自身由于某种原因崩溃了),这些请求直接到了数据库里,直接导致数据库崩溃。
-
缓存击穿:假设缓存中有一个值被极其频繁地访问(该值一般被称为热点数据),当这个值过期后,大量的访问请求到达数据库,导致数据库崩溃。
-
缓存穿透:如果用户访问的数据既不在缓存里,也不在数据库里,后台就无法构建缓存来响应请求。如果大量的这种目标数据既不在缓存里也不在数据库里的请求到来,这些请求一样会到达数据库,导致数据库崩溃。
这三种缓存异常,都是因为各种原因导致缓存命中率不高,使得大量的请求压垮数据库。这些缓存异常的常见解决方法如下:
- 缓存雪崩:
- 均匀设置过期时间:在添加缓存时,在过期时间处添加一个随机数,使得多个缓存不要在同一时间内淘汰
- 互斥锁:在构建缓存时上锁。如果有请求到来,并且缓存未能命中,就先访问锁,如果是未上锁的状态,就正常构建缓存;如果是上锁状态,就等锁结束后再次访问缓存,确认是否命中。(另:实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。)
- 后台多一个线程负责更新缓存,请求只到达缓存,不到数据库。如果缓存未命中,就通过消息队列到后台线程去更新缓存。
- 如果缓存自己崩了,可以启动服务熔断/请求限流或者构建缓存集群来解决。
- 缓存击穿:同缓存雪崩2,3
- 缓存穿透:
- 限制非法请求
- 缓存空值:如果发现数据库没有数据,可以在缓存中对这次请求加一个空值缓存,避免每次都要请求数据库。
- 布隆过滤器
Geecache项目实现日程安排如下:
- LRU缓存淘汰策略
- 单机并发缓存
- HTTP客户端
- 一致性哈希
- 分布式节点
- 防止缓存击穿
- 使用Protubuf通信
另外,该项目可以考虑的扩展方向:
- 多个淘汰策略,比如LFU、ARC
- HTTP通信改为RPC通信
- 细化锁的粒度来提高并发性能
- 实现热点互备来避免热点数据频繁请求影响性能
- 加入etcd
- 加入缓存过期机制
1 Day1 LRU缓存策略实现
常见的缓存策略有FIFO、LRU、LFU、ARC等,该项目使用LRU作为缓存策略。
FIFO算法,顾名思义,先进先出,当缓存满时会自动删除最先进入缓存的数据。但是每次被删除的数据也有可能是最常访问的数据,这一模式并不能很好地匹配缓存的需求。
LFU算法(Least Frequently Used):最少使用算法,每次缓存满时会删除最久未使用过的缓存。这种情况能够很好地满足缓存的需求,但是它所占用的开销算是很大的:不仅要存键值对缓存,还要存这个缓存对应的访问次数,而且每次删除缓存时都需要对访问次数排序。不仅如此,如果对缓存的访问形式突然发生改变,以前经常访问的缓存以后都不再访问,那么要淘汰以前访问次数多的缓存也需要很长的时间。
LRU算法(Least Recently Used)最近最少使用,相对于仅考虑时间的FIFO和仅考虑频率的LFU,该算法认为,如果一个数据被访问了,那么它在未来的一段时间访问的概率就会很高。
LRU算法在Go中的实现,需要一个字典和一个队列(双向链表Cosplay的)组成。队列存储缓存被访问的次序,字典存储具体的数据。每次删除数据时,就将队首的元素出队;每次有缓存被访问时,就将其重新入队,回到队尾。
GoLand的tab默认是4空格,所以看着可能有点怪。
go// src/geecache/lru/lru.go
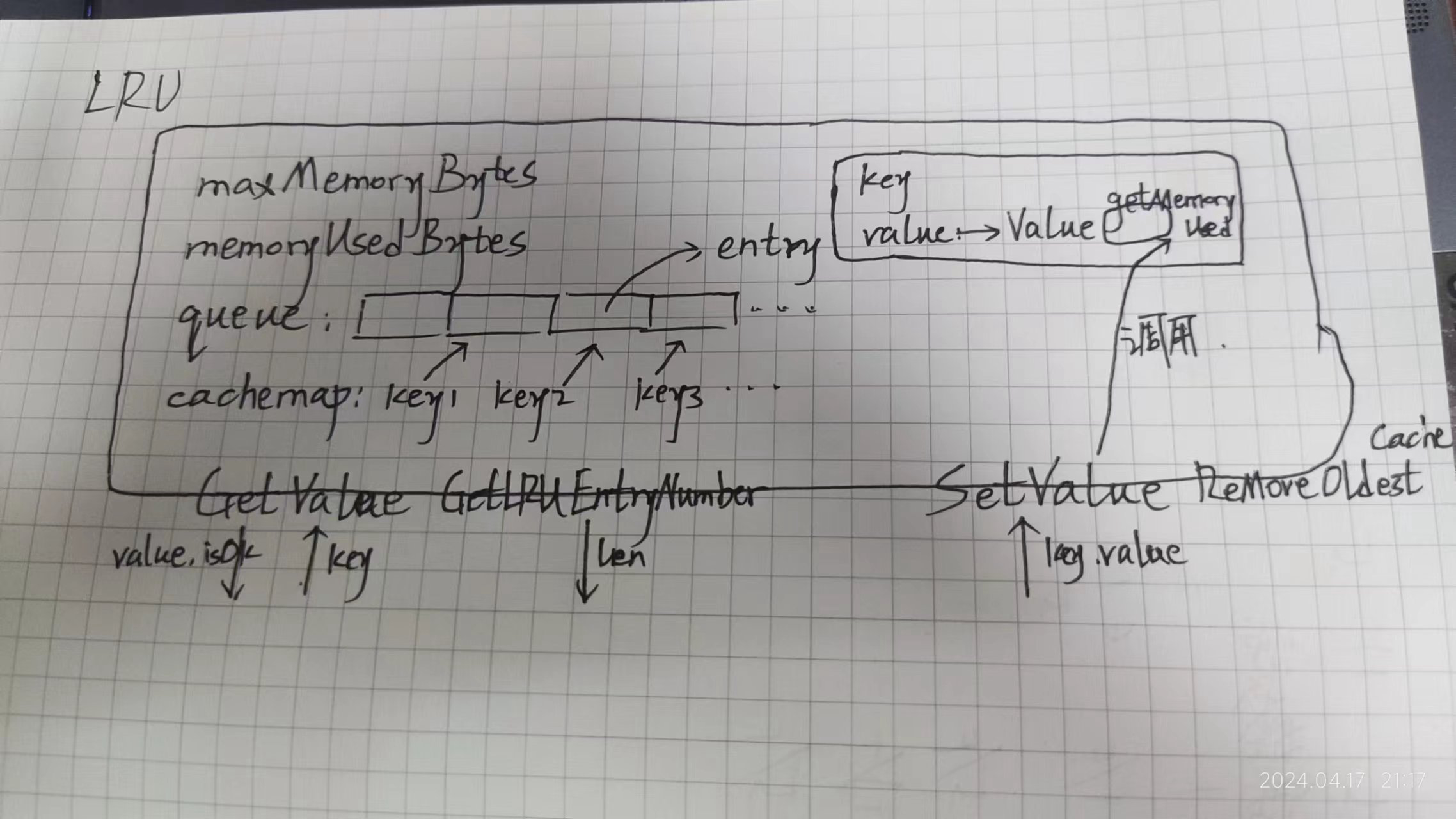
// LRU 采用了LRU策略的缓存类
type LRU struct {
maxMemoryBytes int64 // 允许使用的最大内存
memoryUsedBytes int64 // 当前已经使用的内存
queue *list.List // 队列 存储访问频率
cacheMap map[string]*list.Element // 字典 存储具体的缓存的键值对 这里的值存的是双向链表的元素指针类型 具体的值在链表里
OnEntryDeleted func(key string, value Value) // 当缓存被删除时的回调函数 这种函数类型的默认值就是nil
}
// NewLRU LRU的构造函数
func NewLRU(maxMemoryBytes int64, onEntryDeleted func(string, Value)) (cache *LRU) {
cache = &LRU{
maxMemoryBytes: maxMemoryBytes,
queue: list.New(),
cacheMap: make(map[string]*list.Element),
OnEntryDeleted: onEntryDeleted,
}
return
}
// Value 一条键值对缓存具体要存储的值的接口 该接口的目的是为了确保值对所有类型的通用性
type Value interface {
GetMemoryUsed() int // 返回该缓存的值所占用的内存大小
}
// entry Cache中双向链表所存储的类型
type entry struct {
key string
// 之所以在双向链表中存储键 是为了删除更加方便 能够直接根据键去字典中删除元素
value Value // 值必须是实现了Value接口的类型
}
// 开始实现功能
// GetValue 在缓存里查找值
func (cache *LRU) GetValue(key string) (value Value, isOk bool) {
if element, isOk := cache.cacheMap[key]; isOk {
cache.queue.MoveToFront(element) // 如果元素存在 则移动到队尾 注意双向链表的队尾是相对的 规定Front是队尾即可
entry := element.Value.(*entry) // 这个节点的值取出来 转换为entry类型
return entry.value, true
}
value = nil
isOk = false
return
}
// RemoveOldestCache 淘汰一次缓存
func (cache *LRU) RemoveOldestCache() {
element := cache.queue.Back() // 取出队首元素
if element != nil {
cache.queue.Remove(element) // 从双向链表中移除该元素
cacheEntry := element.Value.(*entry)
delete(cache.cacheMap, cacheEntry.key) // 从字典中移除该键值对
cache.memoryUsedBytes -= int64(len(cacheEntry.key)) + int64(cacheEntry.value.GetMemoryUsed()) // 修改已使用的内存
if cache.OnEntryDeleted != nil { // 如果回调函数不为空 则调用回调函数
cache.OnEntryDeleted(cacheEntry.key, cacheEntry.value)
}
}
}
// SetValue 添加/修改缓存
func (cache *LRU) SetValue(key string, value Value) {
if element, isOk := cache.cacheMap[key]; isOk { // 键存在
cache.queue.MoveToFront(element)
cacheEntry := element.Value.(*entry)
cache.memoryUsedBytes += int64(value.GetMemoryUsed()) - int64(cacheEntry.value.GetMemoryUsed())
cacheEntry.value = value
} else { // 键不存在
element = cache.queue.PushFront(&entry{key: key, value: value})
cache.cacheMap[key] = element
cache.memoryUsedBytes += int64(len(key)) + int64(value.GetMemoryUsed())
}
for cache.memoryUsedBytes > cache.maxMemoryBytes && cache.memoryUsedBytes != 0 { // 看已经使用的缓存内存有多大来淘汰旧缓存
cache.RemoveOldestCache()
}
}
// GetLRUEntryNumber 返回当前已缓存的键值对数量
func (cache *LRU) GetLRUEntryNumber()(len int) {
len = cache.queue.Len()
return
}
3 今日内容结构图
4 测试文件
go// src/geecache/lru/lru_test.go
package lru
import (
"reflect"
"testing"
)
type String string
func (string String) GetMemoryUsed() int { // 要实现Value接口的那个方法 下面才能直接添加什么的
return len(string)
}
func TestCache_GetValue(t *testing.T) {
lru := NewLRU(int64(100), nil)
lru.SetValue("key1", String("1234"))
if value, isOK := lru.GetValue("key1"); !isOK || value != String("1234") {
t.Fatalf("cache hit key1=1234 failed, value actually is %s", value)
}
if _, isOK := lru.GetValue("key2"); isOK {
t.Fatalf("cache miss key2 failed")
}
}
func TestCache_RemoveOldestCache(t *testing.T) {
key1, key2, key3 := "key1", "key2", "key3"
value1, value2, value3 := "value1", "value2", "value3"
cap := len(key1 + key2 + value1 + value2)
lru := NewLRU(int64(cap), nil)
lru.SetValue(key1, String(value1))
lru.SetValue(key2, String(value2))
lru.SetValue(key3, String(value3))
if _, isOk := lru.GetValue(key1); isOk || lru.GetLRUEntryNumber() != 2 {
t.Fatalf("Removeoldest key1 failed")
}
}
func TestCache_OnEntryDeleted (t *testing.T) {
keys := make([]string, 0)
callback := func(key string, value Value) {
keys = append(keys, key)
}
lru := NewLRU(int64(20), callback)
lru.SetValue("key1", String("value1"))
lru.SetValue("key2", String("value2"))
lru.SetValue("key3", String("value3"))
lru.SetValue("key4", String("value3"))
expected := []string {"key1", "key2"}
if !reflect.DeepEqual(expected, keys) {
t.Fatalf("Call OnEvicted failed, expect keys equals to %s, now keys are %s", expected, keys)
}
}
本文作者:御坂19327号
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!