目录
主要内容:
- entry编解码的实现
- 操作文件的接口以及封装文件IO以实现操作文件的接口
- entry+操作文件统一封装并且暴露接口
- Hash数据类型操作总结
该项目大量借鉴RoseDB(意思其实就是没有RoseDB估计我写能写好长时间)
1 Entry编解码的实现
先记录几个方法:
提示
binary.PutVarint():func PutVarint(buf []byte, x int64) int,该方法会将给定的整数x以变长编码的方式转换为字节并且存入buf中,返回的整数值是对x编码后的字节长度。
提示
Go中,切片和切片指针是一个东西,具体看这个图就能理解:
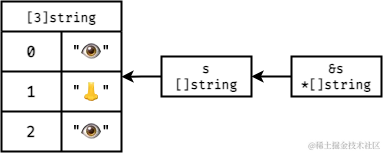
提示
binary.LittleEndian.PutUint32(buffer[:4], crc):func (littleEndian) PutUint32(b []byte, v uint32),以小端字节序将无符号整数v放入字节切片中。小端字节序是一种字节排列方式,它将整数的最低有效字节放在最前面,最高有效字节放在最后面。
提示
binary.Varint:func Varint(buf []byte) (int64, int),在给定的字节数组中从头开始解析,尝试解析出一个整数。第一个返回值是被解析出来的整数,第二个返回值是被解析出来的整数的字节长度。如果第二个返回值等于0,说明给定的字节数组太小;如果小于0,则说明要解析的整数的字节长度超过64位。
提示
crc32.Update:func Update(crc uint32, tab *Table, p []byte) uint32,相当于在已经计算好的crc校验和上,加入新的字节数组继续计算一次。(tab一般为crc32.IEEETable)。
Entry结构如下代码所示。
go// entry.go
package storage
import (
"encoding/binary"
"hash/crc32"
)
// entry编码结构:
// +-------+--------+----------+------------+-----------+-------+---------+
// | crc | type | key size | value size | expiresAt | key | value |
// +-------+--------+----------+------------+-----------+-------+---------+
// |------------------------HEADER----------------------|
// |--------------------------crc check---------------------------|
// header长度:
// crc32 typ kSize vSize expiredAt
// 4 + 1 + 5 + 5 + 10 = 25 (refer to binary.MaxVarintLen32 and binary.MaxVarintLen64)
// MaxEntryHeaderLength 规定Entry头部信息最长长度为25 同时整个Entry长度不能小于25
const MaxEntryHeaderLength = 25
// EntryType 标识entry类型
type EntryType byte
const (
TypeDelete EntryType = iota + 1 // 标识记录删除信息的entry 这个iota写法是让常量从0开始
TypeRecord // 标识记录信息的entry
)
// 因为整个数据库的操作 增删改查 体现在文件上的只有删除和新增两种(改可以通过新增的方式进行覆盖)
// Entry 具体一个Entry所记录的信息
type Entry struct {
Key []byte // 键
Value []byte // 值
EntryType EntryType // entry类型标识
ExpiredAt int64 // 过期时间 这里放时间戳
}
// entryHeaderInfo 一个entry所对应的header信息
type entryHeaderInfo struct {
crc uint32 // 校验和 对剩余部分进行检验
entryType EntryType // entry类型标识
keyLength uint32
valueLength uint32
expiredAt int64 // 过期时间 这里放时间戳
}
// Encode 将entry转换为byte数组 另外返回写入内容的长度 byte数组强制必须大于25 如果不够就用0凑足成25 否则读取文件时不够25会EOF
func (e *Entry) Encode() ([]byte, int) {
if e == nil {
return nil, 0
}
header := make([]byte, MaxEntryHeaderLength)
// 先放头信息里除了校验和之外的其他东西
header[4] = byte(e.EntryType)
index := 5
index += binary.PutVarint(header[index:], int64(len(e.Key)))
index += binary.PutVarint(header[index:], int64(len(e.Value)))
index += binary.PutVarint(header[index:], e.ExpiredAt)
// 再放key和value
size := index + len(e.Key) + len(e.Value)
if size < MaxEntryHeaderLength {
size = MaxEntryHeaderLength
}
buffer := make([]byte, size)
copy(buffer[:index], header[:])
copy(buffer[index:], e.Key)
copy(buffer[index + len(e.Key):], e.Value)
// 最后放crc校验和
crc := crc32.ChecksumIEEE(buffer[4:index + len(e.Key) + len(e.Value)])
binary.LittleEndian.PutUint32(buffer[:4], crc)
return buffer, size
}
// 将给定的byte数组解码为entryHeaderInfo 即Entry的头信息 返回该头信息和头信息的字节长度
func decodeEntryHeader (input []byte) (*entryHeaderInfo, int64) {
if len(input) <= 4 {
return nil, 0
}
result := &entryHeaderInfo{
crc: binary.LittleEndian.Uint32(input[:4]),
entryType: EntryType(input[4]),
}
index := 5
kSize, n := binary.Varint(input[index:])
result.keyLength = uint32(kSize)
index += n
vSize, n := binary.Varint(input[index:])
result.valueLength = uint32(vSize)
index += n
e, n := binary.Varint(input[index:])
result.expiredAt = e
return result, int64(index + n)
}
// getEntryCRC 给定字节数组和Entry 计算该数组+Entry键+Entry值的crc校验和
func getEntryCRC(entry *Entry, h []byte) uint32 {
if entry == nil { return 0 }
result := crc32.ChecksumIEEE(h)
result = crc32.Update(result, crc32.IEEETable, entry.Key)
result = crc32.Update(result, crc32.IEEETable, entry.Value)
return result
}
2 操作文件的接口以及封装文件IO以实现操作文件的接口
go// fileWriter.go
package storage
// FileWriter 定义封装文件操作的基本行为 因为bitcask模型只有对文件的读 追加和整理 所以这里并不涉及对文件的已经写入的数据进行修改
type FileWriter interface {
Write (input []byte, offset int) error // 在文件的指定位置进行写入
Read (buf []byte, offset int) error // 在文件的指定位置进行读取
Sync () error // 强制内存和文件同步一次 以保证一致性
Delete () error // 删除文件
Close () error // 关闭文件
Length () (int64, error) // 返回该文件的长度
}
// attention 实现FileWriter接口的结构体不需要并发安全 因为它和index一一对应 而index会带一个读写锁
这个接口定义了如何对文件进行操作。无论是使用传统的文件IO的方式做,还是MMap方式去做,必须实现这五个接口。
之后是对传统的文件IO的方式进行封装:
go// fileIO.go
package storage
import "os"
type FileIO struct {
file *os.File
}
func NewFileIO (filePath string) (*FileIO, error) {
file, e := os.OpenFile(filePath, os.O_CREATE | os.O_RDWR, 0644)
if e != nil {
// todo logger
return nil, e
}
result := &FileIO{
file: file,
}
return result, nil
}
func (f *FileIO) Write(input []byte, offset int) error {
_, e := f.file.WriteAt(input, int64(offset))
return e
}
func (f *FileIO) Read(buf []byte, offset int) error {
_, e := f.file.ReadAt(buf, int64(offset))
return e
}
func (f *FileIO) Sync() error {
return f.file.Sync()
}
func (f *FileIO) Delete() error {
e := f.file.Close()
if e == nil {
// todo logger
return e
}
return os.Remove(f.file.Name())
// attention *os.File.Remove()只会报PathError 其他的问题导致删除文件不成功的话它报不了错的
// attention *os.File.Name()返回的是当初创建文件时给定的字符串 不论这个字符串是文件绝对路径还是只是文件名
}
func (f *FileIO) Close() error {
return f.file.Close()
}
func (f *FileIO) Length () (int64, error) {
fileStat, e := f.file.Stat()
if e != nil {
return 0, e
}
return fileStat.Size(), nil
}
// 检查接口实现
var _ FileWriter = (*FileIO)(nil)
提示
os.OpenFile:func OpenFile(name string, flag int, perm FileMode) (*File, error),标准库中提供的打开文件的方法。flag如下:
go// Flags to OpenFile wrapping those of the underlying system. Not all
// flags may be implemented on a given system.
const (
// Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
O_RDONLY int = syscall.O_RDONLY // open the file read-only.
O_WRONLY int = syscall.O_WRONLY // open the file write-only.
O_RDWR int = syscall.O_RDWR // open the file read-write.
// The remaining values may be or'ed in to control behavior.
O_APPEND int = syscall.O_APPEND // append data to the file when writing.
O_CREATE int = syscall.O_CREAT // create a new file if none exists.
O_EXCL int = syscall.O_EXCL // used with O_CREATE, file must not exist.
O_SYNC int = syscall.O_SYNC // open for synchronous I/O.
O_TRUNC int = syscall.O_TRUNC // truncate regular writable file when opened.
)
第三个参数指定该文件的权限,第一位表示文件类型,后三位就和Linux中的777概念一致。一般情况下0644够用了。
测试文件:
go// fileIO_test.go
package storage
import "testing"
func TestNewFileIO(t *testing.T) {
file, e := NewFileIO("C:\\Users\\Misaka19327\\OneDrive\\Projects\\GoLandProjects\\MisakaDB\\test.txt")
if e != nil {
t.Log(e)
return
}
defer func() {
e = file.Close()
if e != nil {
t.Log(e)
}
}()
t.Log(file.file.Name())
e = file.Write([]byte{1, 2, 3, 4, 5}, 0)
if e != nil {
t.Log(e)
}
buffer := make([]byte, 5)
e = file.Read(buffer, 0)
if e != nil {
t.Log(e)
} else {
t.Log(buffer)
}
}
3 entry+操作文件统一封装并且暴露接口
数据库所需要的文件操作,就是对一个数据文件写入和读取Entry,同时还需要打开(包括打开已经存在的数据文件),关闭,删除(整理文件时需要)该数据文件。
注意
个人认为文件这里不需要加读写锁,只需要对index加读写锁即可。因为对index的读写一定会一比一地反映到某一个文件上,而如果对index加锁了,那么对文件的读写一定是并发安全的。
gopackage storage
import (
"MisakaDB/src/logger"
storage "MisakaDB/src/storage/file" // 别名写法
"fmt"
"hash/crc32"
"os"
"path"
"path/filepath"
"strconv"
"strings"
)
// FileForData 指定该数据文件存储的数据类型
type FileForData int8
const (
String FileForData = iota
Hash
List
Set
ZSet
)
var (
// 文件名的后缀
fileNameSuffix = map[FileForData]string {
String: "record.string.",
Hash: "record.hash.",
List: "record.list.",
Set: "record.set.",
ZSet: "record.zset.",
}
// 根据文件名解析该文件的存储数据的类型
filenameToDataTypeMap = map[string]FileForData {
"string": String,
"hash": Hash,
"list": List,
"set": Set,
"zset": ZSet,
}
)
// RecordFile 将数据文件抽象为该结构体
type RecordFile struct {
file storage.FileWriter // 对文件进行操作的结构体
fileID uint32 // 文件ID
newestOffset int64 // 该文件写入位置 或者说最新偏移位也可以
dataType FileForData // 该文件存储的键值对的类型
fileMaxSize int64 // 该文件最大的大小
}
// FileIOType 指定文件的读写模式
type FileIOType int8
const (
MMapIOFile FileIOType = iota // MMap方式
TraditionalIOFile // 传统IO方式
)
// NewRecordFile 给定路径 读写模式 存储数据类型 文件ID和文件最大大小 新建一个RecordFile
func NewRecordFile (ioType FileIOType, dataType FileForData, fid uint32, path string, fileMaxSize int64) (*RecordFile, error) {
result := &RecordFile{
fileID: fid,
fileMaxSize: fileMaxSize,
newestOffset: 0,
dataType: dataType,
}
fileFullPath, e := getFileName(fid, dataType, path)
if e != nil {
return nil, e
}
var fileWriter storage.FileWriter
switch ioType {
case MMapIOFile:
return nil, logger.MMapIsNotSupport
case TraditionalIOFile:
fileWriter, e = storage.NewFileIO(fileFullPath)
}
result.file = fileWriter
return result, nil
}
// LoadRecordFileFromDisk 加载一个文件
func LoadRecordFileFromDisk(filePath string, fileMaxSize int64) (*RecordFile, error) {
if _, e := os.Stat(filePath); e != nil {
return nil, logger.FileIsNotExist
}
file, e := storage.NewFileIO(filePath)
if e != nil {
return nil, e
}
fileLen, e := file.Length()
if e != nil {
return nil, e
}
result := &RecordFile{
file: file,
fileMaxSize: fileMaxSize,
newestOffset: fileLen,
}
result.fileID, result.dataType, e = parseFileName(path.Base(filePath))
if e != nil {
return nil, e
}
return result, nil
}
// WriteEntryIntoFile 尝试将Entry写入文件 如果文件剩余大小已经不足以再写入Entry 则返回FileBytesIsMaxedOut错误
func (rf *RecordFile) WriteEntryIntoFile (entry *Entry) error {
writeContent, length := entry.Encode()
if int64(length) + rf.newestOffset > rf.fileMaxSize {
return logger.FileBytesIsMaxedOut
}
e := rf.file.Write(writeContent, int(rf.newestOffset))
rf.newestOffset += int64(length) // 调整偏移位
return e
}
// ReadIntoEntry 在RecordFile中 从给定的offset开始 尝试读取一个完整的Entry并且返回 第二个返回值为当此读取Entry的长度 用以快速定位下次Entry的offset
func (rf *RecordFile) ReadIntoEntry (offset int64) (*Entry, int64, error) {
entryHeaderBytes := make([]byte, MaxEntryHeaderLength)
e := rf.file.Read(entryHeaderBytes, int(offset))
if e != nil {
return nil, 0, e
}
entryHeader, index := decodeEntryHeader(entryHeaderBytes)
result := &Entry{
EntryType: entryHeader.entryType,
ExpiredAt: entryHeader.expiredAt,
Key: make([]byte, entryHeader.keyLength),
Value: make([]byte, entryHeader.valueLength),
}
e = rf.file.Read(result.Key, int(offset + index))
if e != nil {
return nil, 0, e
}
e = rf.file.Read(result.Value, int(offset + index) + int(entryHeader.keyLength))
if e != nil {
return nil, 0, e
}
if crc := getEntryCRC(result, entryHeaderBytes[crc32.Size:index]); crc != entryHeader.crc {
return nil, 0, logger.CRCCheckSumNotPassed
}
entrySize := index + int64(entryHeader.keyLength + entryHeader.valueLength)
if entrySize < MaxEntryHeaderLength { // 注意Entry的最小长度为25
return result, MaxEntryHeaderLength, nil
}
return result, entrySize, nil
}
// Sync 强制刷新缓冲区到文件中
func (rf *RecordFile) Sync () error {
return rf.file.Sync()
}
// Delete 删除该文件
func (rf *RecordFile) Delete () error {
return rf.file.Delete()
}
// Close 关闭该文件
func (rf *RecordFile) Close () error {
return rf.file.Close()
}
// getFileName 给record文件起名 示例名字:record.string.000000001.misaka
func getFileName (fid uint32, dataType FileForData, path string) (string, error) {
if _, ok := fileNameSuffix[dataType]; !ok {
return "", logger.UnSupportDataType
}
fileName := fileNameSuffix[dataType] + fmt.Sprintf("%09d", fid) + ".misaka"
return filepath.Join(path, fileName), nil
}
// parseFileName 给定的FileName中 解析出需要的信息 示例文件名:record.string.000000001.misaka
func parseFileName (fileName string) (uint32, FileForData, error) {
strs := strings.Split(fileName, ".")
resultNum, e := strconv.Atoi(strs[2])
if e != nil {
return 0, String, e
}
return uint32(resultNum), filenameToDataTypeMap[strs[1]], nil
}
提示
const ( String FileForData = iota Hash List Set ZSet )
这种定义常量的写法,iota的含义是从0开始。
测试文件:
gopackage storage
import (
"fmt"
"testing"
)
func TestNewRecordFile(t *testing.T) {
testFile, e := NewRecordFile(TraditionalIOFile, String, 1, "D:\\MisakaDBTest", 65536)
if e != nil {
fmt.Println(e)
return
}
testEntry := &Entry{
Key: []byte("testKey"),
Value: []byte("testValue"),
EntryType: TypeRecord,
ExpiredAt: 0,
}
e = testFile.WriteEntryIntoFile(testEntry)
if e != nil {
fmt.Println(e)
return
}
e = testFile.Sync()
if e != nil {
fmt.Println(e)
return
}
testReadEntry, length, e := testFile.ReadIntoEntry(0)
if e != nil {
fmt.Println(e)
return
}
fmt.Println(string(testReadEntry.Key))
fmt.Println(string(testReadEntry.Value))
fmt.Println(length)
testEntry = &Entry{
Key: []byte("testKey----2"),
Value: []byte("testValue----2"),
EntryType: TypeRecord,
ExpiredAt: 0,
}
e = testFile.WriteEntryIntoFile(testEntry)
if e != nil {
fmt.Println(e)
return
}
e = testFile.Sync()
if e != nil {
fmt.Println(e)
return
}
testReadEntry, length, e = testFile.ReadIntoEntry(25)
if e != nil {
fmt.Println(e)
return
}
fmt.Println(string(testReadEntry.Key))
fmt.Println(string(testReadEntry.Value))
fmt.Println(length)
testEntry = &Entry{
Key: []byte("Key3"),
Value: []byte("Value3"),
EntryType: TypeRecord,
ExpiredAt: 0,
}
e = testFile.WriteEntryIntoFile(testEntry)
if e != nil {
fmt.Println(e)
return
}
e = testFile.Sync()
if e != nil {
fmt.Println(e)
return
}
testReadEntry, length, e = testFile.ReadIntoEntry(59)
if e != nil {
fmt.Println(e)
return
}
fmt.Println(string(testReadEntry.Key))
fmt.Println(string(testReadEntry.Value))
fmt.Println(length)
e = testFile.Close()
if e != nil {
fmt.Println(e)
return
}
}
func TestParseFileName(t *testing.T) {
result1, result2, e := parseFileName("record.string.000000001.misaka")
if e != nil {
t.Log(e)
} else {
t.Log(result1)
t.Log(result2)
}
}
func TestLoadRecordFileFromDisk(t *testing.T) {
rf, e := LoadRecordFileFromDisk("D:\\MisakaDBTest\\record.string.000000001.misaka", 65536)
if e != nil {
t.Log(e)
return
}
t.Log(rf.newestOffset)
testEntry := &Entry{
Key: []byte("testKey5"),
Value: []byte("testValue5"),
EntryType: TypeRecord,
ExpiredAt: 0,
}
e = rf.WriteEntryIntoFile(testEntry)
if e != nil {
fmt.Println(e)
return
}
e = rf.Sync()
if e != nil {
fmt.Println(e)
return
}
testReadEntry, length, e := rf.ReadIntoEntry(84)
if e != nil {
fmt.Println(e)
return
}
fmt.Println(string(testReadEntry.Key))
fmt.Println(string(testReadEntry.Value))
fmt.Println(length)
testReadEntry, length, e = rf.ReadIntoEntry(59)
if e != nil {
fmt.Println(e)
return
}
fmt.Println(string(testReadEntry.Key))
fmt.Println(string(testReadEntry.Value))
fmt.Println(length)
fmt.Println(rf.newestOffset)
}

3 Hash数据操作类型
- HSet:
hset key field value,设置值。如果设置成功则返回1,否则返回0。 - HSetNX:
hsetnx key field value,设置值,但是它只有在field不存在时才能设置成功。 - HGet:
hget key field,获取值,如果key或者field不存在则返回nil。 - HDel:
hdel key field [field ...],删除值,返回被删除的值的数量。 - HLen:
hlen key,获取值的field个数。 - HExists:
hexists key field,判断field是否存在,存在返回1,反之返回0。 - HStrLen:
hstrlen key field,获取value的长度,如果field不存在则返回0。
本文作者:御坂19327号
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!