目录
主要内容:
- 一致性哈希原理
- 一致性哈希实现
1 一致性哈希原理
对于分布式缓存来说,自己接收到请求后,如果在本地查找缓存找不到,下一步肯定是试图请求远程节点来获得缓存,那么假设现在整个分布式缓存算上本节点一共有10个节点,那么本节点在试图请求远程节点时应该请求谁?随机访问肯定不行,有可能节点1访问了节点2,然后发现节点2也没有缓存,再访问节点3,发现节点3也没有缓存……,可见随机访问的效率一定很低。
自定义哈希呢?比如说根据请求的key来计算哈希然后对10求模,求得的数字作为访问节点的依据。这样确实也可以,但是它仍然有一个问题:缓存雪崩。如果这10个节点中有一个节点失效,或者有一个新的节点加入分布式缓存,那么自定义哈希求模就是对9或者11求模了,绝大部分的缓存都会失效,自然会引发缓存雪崩。
一致性哈希就是解决普通哈希的引发缓存雪崩的隐患替代方案。它的大致原理是将请求的key值映射到一个环上,与其同时环上存储着分布式缓存系统的10个节点。确定了key的映射值之后就在环上往后找,找到的第一个节点就是要远程请求的节点。如果这10个节点中有节点失效了,那么请求也会顺延到下一个节点上,而不会引发缓存雪崩。
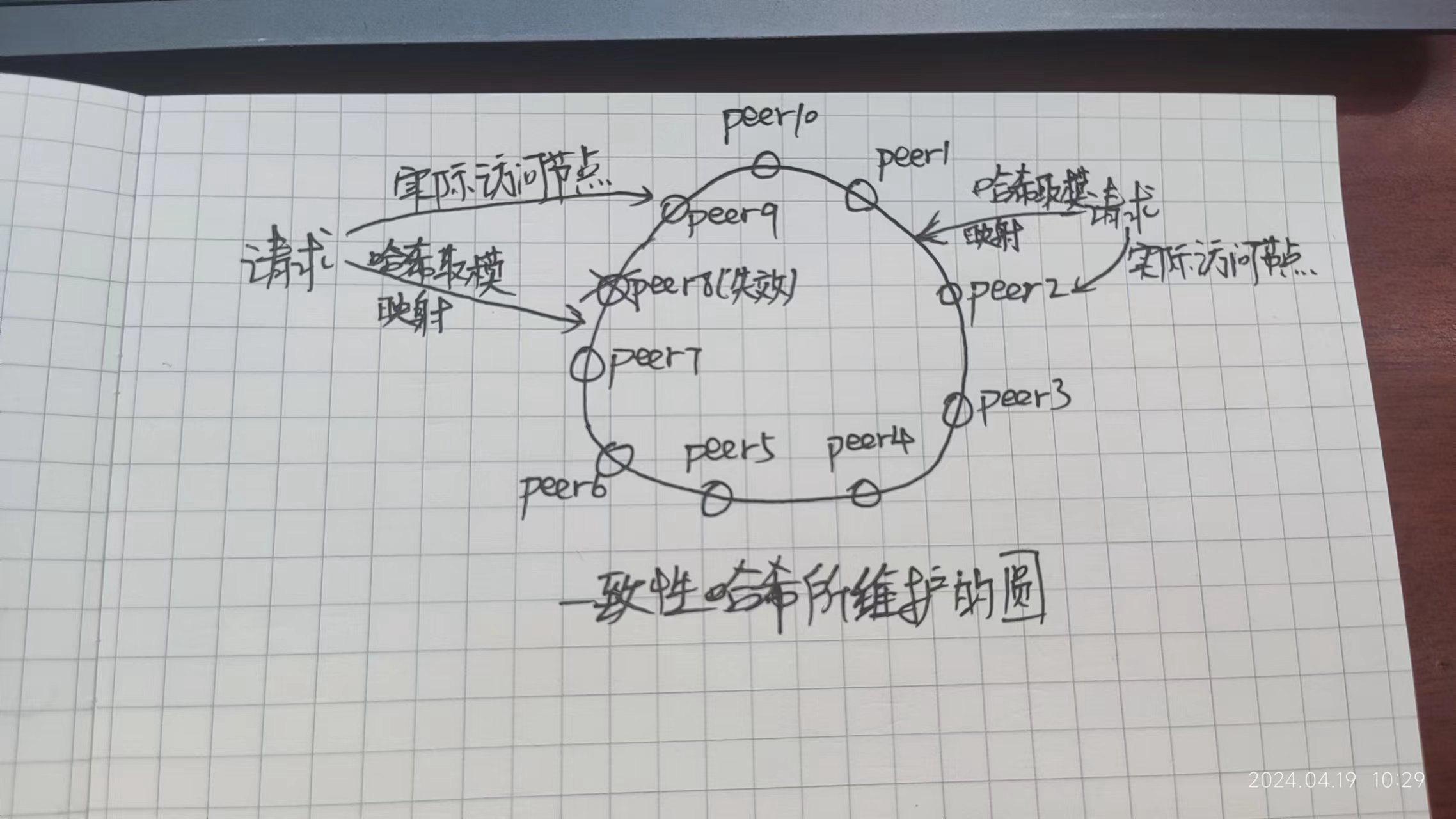
但是一致性哈希也有自己的问题:数据倾斜。还是那个环,还是那10个节点,但是如果这10个节点都只在环的半侧,另外半侧没有节点,这就会造成第一个节点极其繁忙,其余的节点浪费资源。缓解数据倾斜的方法是虚拟节点:为一个节点映射多个虚拟节点,这样减少了节点之间的距离的同时,资源消耗也少:只需要维护节点到虚拟节点的映射关系即可。

2 Day4 一致性哈希实现
先明确在Go里实现一致性哈希要维护什么:
- 哈希函数,用来映射值到环上的
- 一个数组,用来表示环
- 一个字典,用来存储虚节点到节点的映射
- 一个倍数,用来表示一个节点有几个虚节点
一致性哈希能做什么:
- 添加新的节点
- 根据传入的key来返回对应的真实节点
go// src/geecache/consistenthash/consistenthash.go
package consistenthash
import (
"hash/crc32"
"sort"
"strconv"
)
// HashFunc 哈希函数类型
type HashFunc func(data []byte) uint32
// Map 一致性哈希的主要数据结构 这里的一致性哈希维护的节点仅为节点名
type Map struct {
hash HashFunc
replicasNumber int // 真实节点和虚拟节点的映射倍数
keys []int // 一致性哈希的环的抽象版
hashmap map[int]string // 虚拟节点到真实节点的映射
}
// NewMap 一致性哈希的构造函数 默认情况下选择CRC32校验和作为哈希值
func NewMap(hashFunc HashFunc, replicasNumber int) (result *Map) {
result = &Map{
hash: hashFunc,
replicasNumber: replicasNumber,
hashmap: make(map[int]string),
}
if hashFunc == nil {
result.hash = crc32.ChecksumIEEE
}
return
}
// AddRealNode 为一致性哈希添加真实节点(可以一次添加多个真实节点)
func (m *Map) AddRealNode(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicasNumber; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key))) // 这个strconv.Itoa等效FormatInt 从整型转字符串
m.keys = append(m.keys, hash)
m.hashmap[hash] = key // 添加虚拟节点到真实节点的映射
}
}
sort.Ints(m.keys) // 排序
}
// GetRealNodeByKey 根据key来获得真实节点
func (m *Map) GetRealNodeByKey(key string) (result string) {
if len(m.keys) == 0 { // key检查是否有效
return ""
}
keyHash := int(m.hash([]byte(key)))
index := sort.Search(len(m.keys), func(i int) bool { // 二分查找 如果找不到符合条件的就返回len(m.keys)
return m.keys[i] >= keyHash
})
return m.hashmap[m.keys[index % len(m.keys)]] // 去映射里查找真实节点
}
注意代码实现的时候并没有真的实现那个环,而是用一个数组代替。这个数组存储着所有真实节点和其虚拟节点的哈希值,并且调用AddRealNode后都会对该数组进行排序。当传入key后,以二分查找的方式寻找比传入的key的哈希更大的哈希,最后根据找到的下标去keys里找到哈希,再根据哈希去hashmap里找到真实节点。
sort.Search函数,它接收两个参数。第一个是要查找的范围,第二个是一个判断函数,Search函数会根据该函数决定是否继续查找。如果从始至终没有找到一个位置使得判断函数为真,则返回查找范围作为索引。
3 测试文件
gopackage main
import (
"GeeCache/src/geecache/consistenthash"
"strconv"
"testing"
)
func TestHash(t *testing.T) {
test_map := consistenthash.NewMap(func(data []byte) uint32 {
i, _ := strconv.Atoi(string(data))
return uint32(i)
}, 3)
test_map.AddRealNode("2", "4", "6")
test_case := map[string]string {
"2": "2",
"11": "2",
"23": "4",
"27": "2",
}
for k,v := range test_case {
if r := test_map.GetRealNodeByKey(k); r != v {
t.Errorf("Asking for %s, should have yielded %s, actually is %s", k, v, r)
}
}
test_map.AddRealNode("8")
test_case["27"] = "8"
for k,v := range test_case {
if r := test_map.GetRealNodeByKey(k); r != v {
t.Errorf("Asking for %s, should have yielded %s, actually is %s", k, v, r)
}
}
}
本文作者:御坂19327号
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!